【一个总体平均数的置信区间】
拼译:confidence interval for mean of a population
区间估计置信区间的一种。一个总体平均数的置信区间分两种情况。(1)设总体X~N(μ,σ2),方差σ2已知,(X1,X2,…,Xn)是取自X的随机样本,构造统计量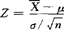 服从标准正态分布,当置信度为1-α时,可查标准正态分布表得双侧α百分位点Zα/2,满足P{-Zα/2≤
服从标准正态分布,当置信度为1-α时,可查标准正态分布表得双侧α百分位点Zα/2,满足P{-Zα/2≤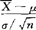 ≤Zα/2}=1-α,进一步改写为P{
≤Zα/2}=1-α,进一步改写为P{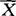 -Zα/2·
-Zα/2·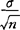 ≤μ≤
≤μ≤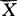 +Zα/2·
+Zα/2·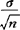 }=1-α,从而μ的置信度为(1-α)(或100(1-α)%)的置信区间为(
}=1-α,从而μ的置信度为(1-α)(或100(1-α)%)的置信区间为(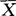 -Zα/2·
-Zα/2·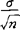 ,
,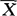 +Zα/2·
+Zα/2·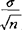 ),或写成μ∈
),或写成μ∈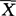 ±Zα/2·
±Zα/2·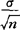 。该置信区间亦可使用于下列情况:若X的分布未知或非正态,当样本容量n足够大(如大于30),上面的统计量Z接近于N(0,1)分布。上述估计区间的半径为Zα/2·
。该置信区间亦可使用于下列情况:若X的分布未知或非正态,当样本容量n足够大(如大于30),上面的统计量Z接近于N(0,1)分布。上述估计区间的半径为Zα/2·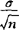 ,是区间估计的精度,依赖置信系数1-α,总体标准差σ或方差σ2,样本容量n三个因素。当1-α越大时,α越小,这时Zα/2会增大;当σ越大时,则半径越大;n越大,半径越小。在σ与α固定时,加大n,提高样本的代表性,从而可提高估计精度。(2)若总体X~N(μ,σ2),但方差σ2未知,构造统计量t=
,是区间估计的精度,依赖置信系数1-α,总体标准差σ或方差σ2,样本容量n三个因素。当1-α越大时,α越小,这时Zα/2会增大;当σ越大时,则半径越大;n越大,半径越小。在σ与α固定时,加大n,提高样本的代表性,从而可提高估计精度。(2)若总体X~N(μ,σ2),但方差σ2未知,构造统计量t=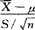 服从自由度为n-1的t分布,这里的S=Sn,即S=
服从自由度为n-1的t分布,这里的S=Sn,即S=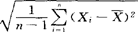 。对预先给出的1-α,查t分布数值表得双侧α分位点tα/2,它满足P{-tα/2≤
。对预先给出的1-α,查t分布数值表得双侧α分位点tα/2,它满足P{-tα/2≤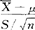 ≤tα/2}=1-α。变形后可得μ的置信度为(1-α)的置信区间为
≤tα/2}=1-α。变形后可得μ的置信度为(1-α)的置信区间为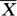 ±tα/2·
±tα/2·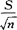 。上面假定的条件“X是正态的”,在小样本时是不能缺少的。但若是大样本,总体X不一定要求正态,上面的估计仍近似可用。
。上面假定的条件“X是正态的”,在小样本时是不能缺少的。但若是大样本,总体X不一定要求正态,上面的估计仍近似可用。
- 心身平行论
- 心身疾病
- 心身相互作用论
- 心身等同论
- 心身问题
- 心身障碍
- 快乐原则
- 快波睡眠
- 快速催眠
- 快速神经学甄别测验
- 念动训练法
- 怀孕心理
- 怀孕期心理变化
- 怀疑精神
- 态度
- 态度变化情境模型
- 态度学习
- 态度类似性
- 态度调查
- 态度量表
- 怔忡
- 思想形成的层次
- 思想形成的激励类型
- 思想形成的结构类型
- 思维
- corchorus capsu laris l.
- Corchorus capsularis L.
- corchorus capsulavis
- Corchorus olitorius
- Corchorus olitorius L.
- Corchorus pyriformis
- corchoside
- corchotoxin
- Corchsularin
- Corchsularose
- Corciano
- Corcieux
- corcinogenesis
- corcione
- corciones
- 满天写满的都是今生的无奈!是什么意思
- 在残忍的世界葬寻我的恋爱是什么意思
- 残城独奏是什么意思
- 幸福过,就好是什么意思
- 真正自我的过程是什么意思
- 浪漫的情感只有两种,相濡以沫、相忘于江湖是什么意思
- 心房—我要有多伤,你才懂得珍惜(二)是什么意思
- 喜欢你是什么意思
- 君已不在,爱又何该?君既不爱,我又何哀?是什么意思
- 炫舞小说:我要做你的男人是什么意思
- 《2012最新流行语,噢耶...》是什么意思
- 你被这世界温柔的爱过是什么意思
- 老婆!因为我喜欢你;所以不想让你受到任何伤害!是什么意思
- 2012这些话好帅,经典得让人心痛!是什么意思
- 看后,你会做吗是什么意思
- 如何分离第三者?
- 老婆出轨了怎么挽回才是对的?
- 老公出轨,老婆该原谅吗
- 老婆出轨该原谅吗?
- 发现老公出轨了,要怎么办?
- 老婆出轨了,如何挽回出轨老婆
- 如何对付第三者,挽救婚姻?
- 应对第三者的挑衅该怎么做?
- 如何击退第三者?
- 对付有心计的第三者应该怎么做?
- 十字爱情情话短信
- 超肉麻的情话短信
- 最能打动女孩的情话短信
- 每天一句小情话短信
- 经营婚姻的6个方法,你试过了吗
- 探秘洐生七星茶的高价之谜
- 探索布吉万象汇的精致下午茶体验
- 心血管健康必备!这些茶叶饮品帮你调理心脏
- 紫砂壶与茶艺的完美结合
- 紫砂壶泡茶的最佳选择:250cc容量适合泡什么茶?
- 灵芝茶的搭配秘诀:这些食材让它更加养生
- 揭秘假普洱茶包装纸的真相
- 抹茶粉的正确饮用时间和方法
- 月经后第三周饮用这些茶饮有助调理身体
- 喜茶小料冻冻的不同之处及选择建议
- 云峰茶叶的独特魅力
- 二十四节气饮茶指南:品味四季变迁
- 探寻吾悦购物中心的下午茶美食天堂
- 探寻茶叶命名的奥秘:一小管子的茶也有独特名称
- 产妇月子期间饮食指南:营养丰富的月子茶推荐